Eino ADK MultiAgent: Supervisor Agent
Supervisor Agent Overview
Import Path
import "github.com/cloudwego/eino/adk/prebuilt/supervisor"
What Is Supervisor Agent?
Supervisor Agent is a centralized multi-agent collaboration pattern composed of one supervisor and multiple subagents. The Supervisor assigns tasks, monitors subagent execution, aggregates results, and decides next actions; subagents focus on executing their tasks and, when done, automatically transfer control back to the Supervisor via WithDeterministicTransferTo.
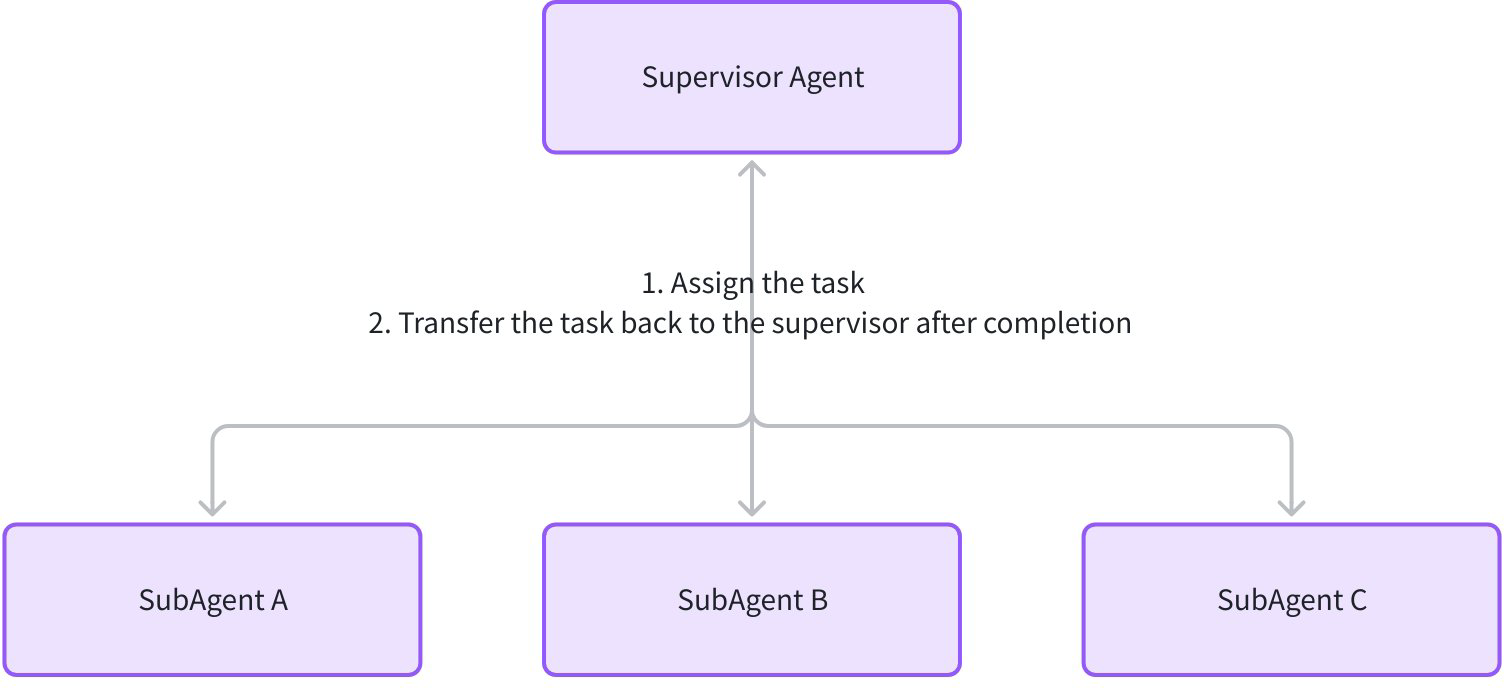
This pattern fits scenarios requiring dynamic coordination among specialized agents to complete complex tasks, such as:
- Research project management (Supervisor assigns research, experiments, and report writing tasks to different subagents)
- Customer service workflows (Supervisor routes based on issue type to tech support, after-sales, sales, etc.)
Supervisor Agent Structure
Core structure of the Supervisor pattern:
- Supervisor Agent: the collaboration core with task assignment logic (rule-based or LLM-driven); manages subagents via
SetSubAgents - SubAgents: each subagent is enhanced by WithDeterministicTransferTo with
ToAgentNamespreset to the Supervisor’s name, ensuring automatic transfer back after completion
Supervisor Agent Features
- Deterministic callback: when a subagent finishes without interruption, WithDeterministicTransferTo automatically triggers a Transfer event to hand control back to the Supervisor, preventing collaboration flow interruption.
- Centralized control: Supervisor manages subagents and dynamically adjusts task assignments based on subagent results (e.g., assign to another subagent or generate final result directly).
- Loose coupling: subagents can be developed, tested, and replaced independently as long as they implement the
Agentinterface and are bound to the Supervisor. - Interrupt/resume support: if subagents or the Supervisor implement
ResumableAgent, the collaboration can resume after interrupts, preserving task context continuity.
Supervisor Agent Run Flow
Typical collaboration flow of the Supervisor pattern:
- Start: Runner triggers the Supervisor with an initial task (e.g., “Write a report on the history of LLMs”)
- Assign: Supervisor transfers the task via Transfer event to a designated subagent (e.g., “ResearchAgent”)
- Execute: Subagent performs its task (e.g., research LLM key milestones) and generates result events
- Auto-callback: upon completion, WithDeterministicTransferTo triggers a Transfer event back to Supervisor
- Process result: Supervisor receives subagent results and decides next steps (e.g., transfer to “WriterAgent” for further processing, or output final result directly)
Supervisor Agent Usage Example
Scenario
Create a research report generation system:
- Supervisor: given a research topic from user input, assigns tasks to “ResearchAgent” and “WriterAgent”, and aggregates the final report
- ResearchAgent: generates a research plan (e.g., key stages of LLM development)
- WriterAgent: writes a complete report based on the research plan
Code Implementation
Step 1: Implement SubAgents
First create two subagents responsible for research and writing tasks:
// ResearchAgent: generate a research plan
func NewResearchAgent(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "ResearchAgent",
Description: "Generates a detailed research plan for a given topic.",
Instruction: `
You are a research planner. Given a topic, output a step-by-step research plan with key stages and milestones.
Output ONLY the plan, no extra text.`,
Model: model,
})
return agent
}
// WriterAgent: write a report based on the plan
func NewWriterAgent(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "WriterAgent",
Description: "Writes a report based on a research plan.",
Instruction: `
You are an academic writer. Given a research plan, expand it into a structured report with details and analysis.
Output ONLY the report, no extra text.`,
Model: model,
})
return agent
}
Step 2: Implement Supervisor Agent
Create the Supervisor Agent with task assignment logic (simplified here as rule-based: first assign to ResearchAgent, then to WriterAgent):
// ReportSupervisor: coordinate research and writing tasks
func NewReportSupervisor(model model.ToolCallingChatModel) adk.Agent {
agent, _ := adk.NewChatModelAgent(context.Background(), &adk.ChatModelAgentConfig{
Name: "ReportSupervisor",
Description: "Coordinates research and writing to generate a report.",
Instruction: `
You are a project supervisor. Your task is to coordinate two sub-agents:
- ResearchAgent: generates a research plan.
- WriterAgent: writes a report based on the plan.
Workflow:
1. When receiving a topic, first transfer the task to ResearchAgent.
2. After ResearchAgent finishes, transfer the task to WriterAgent with the plan as input.
3. After WriterAgent finishes, output the final report.`,
Model: model,
})
return agent
}
Step 3: Compose Supervisor and SubAgents
Use NewSupervisor to compose the Supervisor and subagents:
import (
"context"
"github.com/cloudwego/eino-ext/components/model/openai"
"github.com/cloudwego/eino/adk"
"github.com/cloudwego/eino/adk/prebuilt/supervisor"
"github.com/cloudwego/eino/components/model"
"github.com/cloudwego/eino/schema"
)
func main() {
ctx := context.Background()
// 1. Create LLM model (e.g., GPT-4o)
model, _ := openai.NewChatModel(ctx, &openai.ChatModelConfig{
APIKey: "YOUR_API_KEY",
Model: "gpt-4o",
})
// 2. Create subagents and Supervisor
researchAgent := NewResearchAgent(model)
writerAgent := NewWriterAgent(model)
reportSupervisor := NewReportSupervisor(model)
// 3. Compose Supervisor and subagents
supervisorAgent, _ := supervisor.New(ctx, &supervisor.Config{
Supervisor: reportSupervisor,
SubAgents: []adk.Agent{researchAgent, writerAgent},
})
// 4. Run Supervisor pattern
iter := supervisorAgent.Run(ctx, &adk.AgentInput{
Messages: []adk.Message{
schema.UserMessage("Write a report on the history of Large Language Models."),
},
EnableStreaming: true,
})
// 5. Consume event stream (print results)
for {
event, ok := iter.Next()
if !ok {
break
}
if event.Output != nil && event.Output.MessageOutput != nil {
msg, _ := event.Output.MessageOutput.GetMessage()
println("Agent[" + event.AgentName + "]:\n" + msg.Content + "\n===========")
}
}
}
Run Result
Agent[ReportSupervisor]:
===========
Agent[ReportSupervisor]:
successfully transferred to agent [ResearchAgent]
===========
Agent[ResearchAgent]:
1. **Scope Definition & Background Research**
- Task: Define "Large Language Model" (LLM) for the report (e.g., size thresholds, key characteristics: transformer-based, large-scale pretraining, general-purpose).
- Task: Identify foundational NLP/AI concepts pre-LLMs (statistical models, early neural networks, word embeddings) to contextualize origins.
- Milestone: 3-day literature review of academic definitions, industry reports, and AI historiographies to finalize scope.
2. **Chronological Periodization**
- Task: Divide LLM history into distinct eras (e.g., Pre-2017: Pre-transformer foundations; 2017-2020: Transformer revolution & early LLMs; 2020-Present: Scaling & mainstream adoption).
- Task: Map key events, models, and breakthroughs per era (e.g., 2017: "Attention Is All You Need"; 2018: GPT-1/BERT; 2020: GPT-3; 2022: ChatGPT; 2023: Llama 2).
- Milestone: 10-day timeline draft with annotated model releases, research papers, and technological shifts.
3. **Key Technical Milestones**
- Task: Deep-dive into critical innovations (transformer architecture, pretraining-fine-tuning paradigm, scaling laws, in-context learning).
- Task: Extract details from seminal papers (authors, institutions, methodologies, performance benchmarks).
- Milestone: 1-week analysis of 5-7 foundational papers (e.g., Vaswani et al. 2017; Radford et al. 2018; Devlin et al. 2018) with technical summaries.
4. **Stakeholder Mapping**
- Task: Identify key organizations (OpenAI, Google DeepMind, Meta AI, Microsoft Research) and academic labs (Stanford, Berkeley) driving LLM development.
- Task: Document institutional contributions (e.g., OpenAI's GPT series, Google's BERT/PaLM, Meta's Llama) and research priorities (open vs. closed models).
- Milestone: 5-day stakeholder profile draft with org-specific timelines and model lineages.
5. **Technical Evolution & Innovation Trajectory**
- Task: Analyze shifts in architecture (from RNNs/LSTMs to transformers), training paradigms (pretraining + fine-tuning → instruction tuning → RLHF), and compute scaling (parameters, data size, GPU usage over time).
- Task: Link technical changes to performance improvements (e.g., GPT-1 (124M params) vs. GPT-4 (100B+ params): task generalization, emergent abilities).
- Milestone: 1-week technical trajectory report with data visualizations (param scaling, benchmark scores over time).
6. **Impact & Societal Context**
- Task: Research LLM impact on NLP tasks (translation, summarization, QA) and beyond (education, content creation, policy).
- Task: Document cultural/industry shifts (rise of prompt engineering, "AI-native" products, public perception post-ChatGPT).
- Milestone: 5-day impact analysis integrating case studies (e.g., GitHub Copilot, healthcare LLMs) and media/scholarly discourse.
7. **Challenges & Critiques (Historical Perspective)**
- Task: Track historical limitations (pre-2020: data sparsity, task specificity; post-2020: bias, misinformation, energy use) and responses (e.g., 2019: BERT bias audits; 2023: EU AI Act).
- Task: Cite key critiques (e.g., "On the Dangers of Stochastic Parrots," 2021) and industry/academic reactions.
- Milestone: 5-day challenge timeline linking issues to their emergence and mitigation efforts.
8. **Synthesis & Narrative Drafting**
- Task: Integrate chronological, technical, and societal data into a coherent narrative (origins → revolution → scaling → mainstream impact).
- Task: Outline report structure (Abstract, Introduction, Era-by-Era Analysis, Key Innovations, Stakeholders, Impact, Challenges, Conclusion).
- Milestone: 1-week first draft of full report (8,000–10,000 words).
9. **Validation & Fact-Checking**
- Task: Verify model release dates, paper citations, parameter counts, and stakeholder claims via primary sources (original papers, official press releases, archived GitHub repos).
- Task: Cross-check with secondary sources (AI history books, expert interviews, peer-reviewed historiographies).
- Milestone: 3-day validation report flagging/correcting inaccuracies.
10. **Finalization & Revision**
- Task: Edit for clarity, narrative flow, and consistency; refine visuals (timelines, param scaling charts).
- Task: Format references (APA/MLA) and appendices (model comparison table, key paper list).
- Milestone: 2-day final report submission.
===========
Agent[ResearchAgent]:
===========
Agent[ResearchAgent]:
successfully transferred to agent [ReportSupervisor]
===========
Agent[ReportSupervisor]:
===========
Agent[ReportSupervisor]:
successfully transferred to agent [WriterAgent]
===========
Agent[WriterAgent]:
# The History of Large Language Models: From Foundations to Mainstream Revolution
## Abstract
Large Language Models (LLMs) represent one of the most transformative technological innovations of the 21st century, enabling machines to understand, generate, and manipulate human language with unprecedented fluency. This report traces the historical trajectory of LLMs, from their conceptual roots in early natural language processing (NLP) to their current status as mainstream tools. It examines key technical milestones—including the invention of the transformer architecture, the rise of pretraining-fine-tuning paradigms, and the scaling of model parameters—and contextualizes these within the contributions of academic labs and tech giants. The report also analyzes societal impacts, from revolutionizing NLP tasks to sparking debates over bias, misinformation, and AI regulation. By synthesizing chronological, technical, and cultural data, this history reveals how LLMs evolved from niche research experiments to agents of global change.
## 1. Introduction: Defining Large Language Models
A **Large Language Model (LLM)** is a type of machine learning model designed to process and generate human language by learning patterns from massive text datasets. Key characteristics include: (1) a transformer-based architecture, enabling parallel processing of text sequences; (2) large-scale pretraining on diverse corpora (e.g., books, websites, articles); (3) general-purpose functionality, allowing adaptation to tasks like translation, summarization, or dialogue without task-specific engineering; and (4) scale, typically defined by billions (or tens of billions) of parameters (adjustable weights that capture linguistic patterns).
LLMs emerged from decades of NLP research, building on foundational concepts like statistical models (e.g., n-grams), early neural networks (e.g., recurrent neural networks [RNNs]), and word embeddings (e.g., Word2Vec, GloVe). By the 2010s, these predecessors had laid groundwork for "language understanding," but were limited by task specificity (e.g., a model trained for translation could not summarize text) and data sparsity. LLMs addressed these gaps by prioritizing scale, generality, and architectural innovation—ultimately redefining the boundaries of machine language capability.
## 2. Era-by-Era Analysis: The Evolution of LLMs
### 2.1 Pre-2017: Pre-Transformer Foundations (1950s–2016)
The roots of LLMs lie in mid-20th-century NLP, when researchers first sought to automate language tasks. Early efforts relied on rule-based systems (e.g., 1950s machine translation using syntax rules) and statistical methods (e.g., 1990s n-gram models for speech recognition). By the 2010s, neural networks gained traction: RNNs and long short-term memory (LSTM) models (Hochreiter & Schmidhuber, 1997) enabled sequence modeling, while word embeddings (Mikolov et al., 2013) represented words as dense vectors, capturing semantic relationships.
Despite progress, pre-2017 models faced critical limitations: RNNs/LSTMs processed text sequentially, making them slow to train and unable to handle long-range dependencies (e.g., linking "it" in a sentence to a noun paragraphs earlier). Data was also constrained: models like Word2Vec trained on millions, not billions, of tokens. These bottlenecks set the stage for a paradigm shift.
### 2.2 2017–2020: The Transformer Revolution and Early LLMs
The year 2017 marked the dawn of the LLM era with the publication of *"Attention Is All You Need"* (Vaswani et al.), which introduced the **transformer architecture**. Unlike RNNs, transformers use "self-attention" mechanisms to weigh the importance of different words in a sequence simultaneously, enabling parallel computation and capturing long-range dependencies. This breakthrough reduced training time and improved performance on language tasks.
#### Key Models and Breakthroughs:
- **2018**: OpenAI released **GPT-1** (Radford et al.), the first transformer-based LLM. With 124 million parameters, it introduced the "pretraining-fine-tuning" paradigm: pretraining on a large unlabeled corpus (BooksCorpus) to learn general language patterns, then fine-tuning on task-specific labeled data (e.g., sentiment analysis).
- **2018**: Google published **BERT** (Devlin et al.), a bidirectional transformer that processed text from left-to-right *and* right-to-left, outperforming GPT-1 on context-dependent tasks like question answering. BERT's success popularized "contextual embeddings," where word meaning depends on surrounding text (e.g., "bank" as a financial institution vs. a riverbank).
- **2019**: OpenAI scaled up with **GPT-2** (1.5 billion parameters), demonstrating improved text generation but sparking early concerns about misuse (OpenAI initially delayed full release over fears of disinformation).
- **2020**: Google's **T5** (Text-to-Text Transfer Transformer) unified NLP tasks under a single "text-to-text" framework, simplifying model adaptation.
### 2.3 2020–Present: Scaling, Emergence, and Mainstream Adoption
The 2020s saw LLMs transition from research curiosities to global phenomena, driven by exponential scaling of parameters, data, and compute.
#### Key Developments:
- **2020**: OpenAI's **GPT-3** (175 billion parameters) marked a turning point. Trained on 45 TB of text, it exhibited "few-shot" and "zero-shot" learning. GPT-3's API release introduced LLMs to developers.
- **2022**: **ChatGPT** (GPT-3.5) brought LLMs to the public with **RLHF** alignment.
- **2023**: Meta's **Llama 2** opened weights for research and commercial use; OpenAI's **GPT-4** expanded multimodality and reasoning.
- **2023–2024**: Scaling race continued (PaLM 2, Claude 2, Mistral, Falcon); compute usage skyrocketed.
===========
Agent[WriterAgent]:
===========
Agent[WriterAgent]:
successfully transferred to agent [ReportSupervisor]
===========
WithDeterministicTransferTo
What Is WithDeterministicTransferTo?
WithDeterministicTransferTo is an ADK agent enhancer that injects Transfer capability. It lets developers predefine a fixed transfer path for a target agent so that, upon completion (not interrupted), it automatically generates a Transfer event to route the task to predefined destination agents.
This capability is the foundation of the Supervisor Agent collaboration pattern, ensuring subagents reliably hand control back to the Supervisor, forming a “assign-execute-feedback” closed-loop collaboration flow.
WithDeterministicTransferTo Core Implementation
Config Structure
Define core parameters for task transfer via DeterministicTransferConfig:
// Wrapper method
func AgentWithDeterministicTransferTo(_ context.Context, config *DeterministicTransferConfig) Agent
// Config details
type DeterministicTransferConfig struct {
Agent Agent // Target agent to enhance
ToAgentNames []string // Destination agent names to transfer to after completion
}
Agent: the original agent to add transfer capability toToAgentNames: destination agent names (in order) to automatically transfer to when the agent completes without interruption
Agent Wrapping
WithDeterministicTransferTo wraps the original agent. Depending on whether it implements ResumableAgent (supports interrupt/resume), it returns agentWithDeterministicTransferTo or resumableAgentWithDeterministicTransferTo, ensuring enhanced capability is compatible with the agent’s original features (like Resume method).
The wrapped agent overrides Run method (and Resume for ResumableAgent), appending Transfer events after the original agent’s event stream:
// Wrapper for a regular Agent
type agentWithDeterministicTransferTo struct {
agent Agent // Original agent
toAgentNames []string // Destination agent names
}
// Run: execute original agent and append Transfer event after completion
func (a *agentWithDeterministicTransferTo) Run(ctx context.Context, input *AgentInput, options ...AgentRunOption) *AsyncIterator[*AgentEvent] {
aIter := a.agent.Run(ctx, input, options...)
iterator, generator := NewAsyncIteratorPair[*AgentEvent]()
// Asynchronously process original event stream and append Transfer event
go appendTransferAction(ctx, aIter, generator, a.toAgentNames)
return iterator
}
For ResumableAgent, additionally implement Resume method to ensure deterministic transfer on resume completion:
type resumableAgentWithDeterministicTransferTo struct {
agent ResumableAgent // Resumable original agent
toAgentNames []string // Destination agent names
}
// Resume: resume original agent and append Transfer event after completion
func (a *resumableAgentWithDeterministicTransferTo) Resume(ctx context.Context, info *ResumeInfo, opts ...AgentRunOption) *AsyncIterator[*AgentEvent] {
aIter := a.agent.Resume(ctx, info, opts...)
iterator, generator := NewAsyncIteratorPair[*AgentEvent]()
go appendTransferAction(ctx, aIter, generator, a.toAgentNames)
return iterator
}
Append Transfer Event to Event Stream
appendTransferAction is the core logic for deterministic transfer. It consumes the original agent’s event stream and, when the agent task finishes normally (not interrupted), automatically generates and sends Transfer events to destination agents:
func appendTransferAction(ctx context.Context, aIter *AsyncIterator[*AgentEvent], generator *AsyncGenerator[*AgentEvent], toAgentNames []string) {
defer func() {
// Exception handling: capture panic and pass error via event
if panicErr := recover(); panicErr != nil {
generator.Send(&AgentEvent{Err: safe.NewPanicErr(panicErr, debug.Stack())})
}
generator.Close() // Close generator when event stream ends
}()
interrupted := false
// 1. Forward all original agent events
for {
event, ok := aIter.Next()
if !ok { // Original event stream ended
break
}
generator.Send(event) // Forward event to caller
// Check for interrupt (e.g., InterruptAction)
if event.Action != nil && event.Action.Interrupted != nil {
interrupted = true
} else {
interrupted = false
}
}
// 2. If not interrupted and destination agents exist, generate Transfer events
if !interrupted && len(toAgentNames) > 0 {
for _, toAgentName := range toAgentNames {
// Generate transfer messages (system tip + Transfer action)
aMsg, tMsg := GenTransferMessages(ctx, toAgentName)
// Send system tip event (notify user of task transfer)
aEvent := EventFromMessage(aMsg, nil, schema.Assistant, "")
generator.Send(aEvent)
// Send Transfer action event (trigger task transfer)
tEvent := EventFromMessage(tMsg, nil, schema.Tool, tMsg.ToolName)
tEvent.Action = &AgentAction{
TransferToAgent: &TransferToAgentAction{
DestAgentName: toAgentName, // Destination agent name
},
}
generator.Send(tEvent)
}
}
}
Key Logic:
- Event forwarding: all events from the original agent (thinking, tool calls, output results) are forwarded intact, ensuring business logic is unaffected
- Interrupt check: if the agent is interrupted during execution (e.g.,
InterruptAction), Transfer is not triggered (interrupt means task did not complete normally) - Transfer event generation: after task completes normally, for each
ToAgentNames, generate two events:- System tip event (
schema.Assistantrole): notify user that task will transfer to destination agent - Transfer action event (
schema.Toolrole): carryTransferToAgentActionto trigger ADK runtime to transfer task to the agent specified byDestAgentName
- System tip event (
Summary
WithDeterministicTransferTo provides reliable task transfer capability for agents, serving as the core foundation for building the Supervisor pattern; the Supervisor pattern achieves efficient multi-agent collaboration through centralized coordination and deterministic callback, significantly reducing development and maintenance costs for complex tasks. Combining both, developers can quickly build flexible, extensible multi-agent systems.